1. Troubleshooting Pods
Most of the time, the issue is in the Pod itself.
You should make sure that your Pods are Running and Ready.
How do you check that?
bash
kubectl get pods
NAME READY STATUS RESTARTS AGE
app1 0/1 ImagePullBackOff 0 47h
app2 0/1 Error 0 47h
app3-76f9fcd46b-xbv4k 1/1 Running 1 47hIn the output above, the last Pod is Running and Ready — however, the first two Pods are neither Running nor Ready.
How do you investigate on what went wrong?
There are four useful commands to troubleshoot Pods:
-
kubectl logs <pod name>is helpful to retrieve the logs of the containers of the Pod. -
kubectl describe pod <pod name>is useful to retrieve a list of events associated with the Pod. -
kubectl get pod <pod name>is useful to extract the YAML definition of the Pod as stored in Kubernetes. -
kubectl exec -ti <pod name> -- bashis useful to run an interactive command within one of the containers of the Pod.
Which one should you use?
There isn't a one-size-fits-all.
Instead, you should use a combination of them.

Common Pods errors
Pods can have startup and runtime errors.
Startup errors include:
- ImagePullBackoff
- ImageInspectError
- ErrImagePull
- ErrImageNeverPull
- RegistryUnavailable
- InvalidImageName
Runtime errors include:
- CrashLoopBackOff
- RunContainerError
- KillContainerError
- VerifyNonRootError
- RunInitContainerError
- CreatePodSandboxError
- ConfigPodSandboxError
- KillPodSandboxError
- SetupNetworkError
- TeardownNetworkError
Some errors are more common than others.
The following is a list of the most common error and how you can fix them.
ImagePullBackOff
This error appears when Kubernetes isn't able to retrieve the image for one of the containers of the Pod.
There are three common culprits:
- The image name is invalid — as an example, you misspelt the name, or the image does not exist.
- You specified a non-existing tag for the image.
- The image that you're trying to retrieve belongs to a private registry, and Kubernetes doesn't have credentials to access it.
The first two cases can be solved by correcting the image name and tag.
For the last, you should add the credentials to your private registry in a Secret and reference it in your Pods.
The official documentation has an example about how you could to that.
CrashLoopBackOff
If the container can't start, then Kubernetes shows the CrashLoopBackOff message as a status.
Usually, a container can't start when:
- There's an error in the application that prevents it from starting.
- You misconfigured the container.
- The Liveness probe failed too many times.
You should try and retrieve the logs from that container to investigate why it failed.
If you can't see the logs because your container is restarting too quickly, you can use the following command:
bash
kubectl logs <pod-name> --previousWhich prints the error messages from the previous container.
RunContainerError
The error appears when the container is unable to start.
That's even before the application inside the container starts.
The issue is usually due to misconfiguration such as:
- Mounting a not-existent volume such as ConfigMap or Secrets.
- Mounting a read-only volume as read-write.
You should use kubectl describe pod <pod-name> to inspect and analyse the errors.
Pods in a Pending state
When you create a Pod, the Pod stays in the Pending state.
Why?
Assuming that your scheduler component is running fine, here are the causes:
- The cluster doesn't have enough resources such as CPU and memory to run the Pod.
- The current Namespace has a ResourceQuota object and creating the Pod will make the Namespace go over the quota.
- The Pod is bound to a Pending PersistentVolumeClaim.
Your best option is to inspect the Events section in the kubectl describe command:
bash
kubectl describe pod <pod name>For errors that are created as a result of ResourceQuotas, you can inspect the logs of the cluster with:
bash
kubectl get events --sort-by=.metadata.creationTimestampPods in a not Ready state
If a Pod is Running but not Ready it means that the Readiness probe is failing.
When the Readiness probe is failing, the Pod isn't attached to the Service, and no traffic is forwarded to that instance.
A failing Readiness probe is an application-specific error, so you should
inspect the Events section in kubectl describe to identify the error.
2. Troubleshooting Services
If your Pods are Running and Ready, but you're still unable to receive a response from your app, you should check if the Service is configured correctly.
Services are designed to route the traffic to Pods based on their labels.
So the first thing that you should check is how many Pods are targeted by the Service.
You can do so by checking the Endpoints in the Service:
bash
kubectl describe service my-service
Name: my-service
Namespace: default
Selector: app=my-app
IP: 10.100.194.137
Port: <unset> 80/TCP
TargetPort: 8080/TCP
Endpoints: 172.17.0.5:8080
An endpoint is a pair of <ip address:port>, and there should be at least one — when the Service targets (at least) a
Pod.
If the "Endpoints" section is empty, there are two explanations:
- You don't have any Pod running with the correct label (hint: you should check if you are in the right namespace).
-
You have a typo in the
selectorlabels of the Service.
If you see a list of endpoints, but still can't access your application,
then the targetPort in your service is the likely culprit.
How do you test the Service?
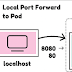
Regardless of the type of Service, you can use kubectl port-forward to connect to it:
bash
kubectl port-forward service/<service-name> 3000:80Where:
-
<service-name>is the name of the Service. -
3000is the port that you wish to open on your computer. -
80is the port exposed by the Service.
3. Troubleshooting Ingress
If you've reached this section, then:
- The Pods are Running and Ready.
- The Service distributes the traffic to the Pod.
But you still can't see a response from your app.
It means that most likely, the Ingress is misconfigured.
Since the Ingress controller is a third-party component in the cluster, there are different debugging techniques depending on the type of Ingress controller.
But before diving into Ingress specific tools, there's something straightforward that you could check.
The Ingress uses the service.name and service.port to connect to the Service.
You should check that those are correctly configured.
You can inspect that the Ingress is correctly configured with:
bash
kubectl describe ingress my-ingress
Name: my-ingress
Namespace: default
Rules:
Host Path Backends
---- ---- --------
*
/ my-service:80 (<error: endpoints "my-service" not found>)If the Backend column is empty, then there must be an error in the configuration.
If you can see the endpoints in the Backend column, but still can't access the application, the issue is likely to be:
- How you exposed your Ingress to the public internet.
- How you exposed your cluster to the public internet.
You can isolate infrastructure issues from Ingress by connecting to the Ingress Pod directly.
First, retrieve the Pod for your Ingress controller (which could be located in a different namespace):
bash
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS
kube-system coredns-5644d7b6d9-jn7cq 1/1 Running
kube-system etcd-minikube 1/1 Running
kube-system kube-apiserver-minikube 1/1 Running
kube-system kube-controller-manager-minikube 1/1 Running
kube-system kube-proxy-zvf2h 1/1 Running
kube-system kube-scheduler-minikube 1/1 Running
kube-system nginx-ingress-controller-6fc5bcc 1/1 RunningDescribe it to retrieve the port:
bash
kubectl describe pod nginx-ingress-controller-6fc5bcc
--namespace kube-system \
| grep Ports
Ports: 80/TCP, 443/TCP, 8443/TCP
Host Ports: 80/TCP, 443/TCP, 0/TCPFinally, connect to the Pod:
bash
kubectl port-forward nginx-ingress-controller-6fc5bcc 3000:80 --namespace kube-system
Forwarding from 127.0.0.1:3000 -> 80
Forwarding from [::1]:3000 -> 80At this point, every time you visit port 3000 on your computer, the request is forwarded to port 80 on the Pod.
Does it work now?
- If it does, the issue is in the infrastructure. You should investigate how the traffic is routed to your cluster.
- If it doesn't work, the problem is in the Ingress controller. You should debug the Ingress.
If you still can't get the Ingress controller to work, you should start debugging it.
There are many different versions of Ingress controllers.
Popular options include Nginx, HAProxy, Traefik, etc.
You should consult the documentation of your Ingress controller to find a troubleshooting guide.
Since Ingress Nginx is the most popular Ingress controller, we included a few tips for it in the next section.
Debugging Ingress Nginx
The Ingress-nginx project has an official plugin for Kubectl.
You can use kubectl ingress-nginx to:
- Inspect logs, backends, certs, etc.
- Connect to the Ingress.
- Examine the current configuration.
The three commands that you should try are:
-
kubectl ingress-nginx lint, which checks thenginx.conf. -
kubectl ingress-nginx backend, to inspect the backend (similar tokubectl describe ingress <ingress-name>). -
kubectl ingress-nginx logs, to check the logs.
Please notice that you might need to specify the correct namespace for your Ingress controller with
--namespace <name>.
Be the first to be notified when a new article or Kubernetes experiment is published.